Paper Capture & OCR : reconnaissance optique de caractères
Reconnaissance optique de caractère (OCR) avec Acrobat
Importer ou ouvrir un fichier image dans Acrobat, effectuer la reconnaissance optique de caractère et conserver un fac-similé numérique de l’original :
Si vous avez un scanner compatible, vous pourrez numériser un document contenant du texte directement depuis Acrobat via le menu Fichier > Créer un fichier PDF > A partir d’un scanner…
PDF/A : depuis Acrobat 8 il est possible de générer directement des fichiers respectant cette norme ISO d’archivage en cochant la case idoine.
La méthode d’utilisation du scanner n’est pas à l’ordre du jour, mais il faudra numériser avec une résolution comprise entre 200 et 600 ppp (Point Par Pouce ou ‘dpi’ en anglais). La résolution doit être augmentée si l’original comporte des petits caractères ou est de mauvaise qualité, et inversement. 300 ppp donnent généralement de bons résultats sur des coupures de journaux
Faute de scanner ou faute de scanner compatible, il est possible d’importer des fichiers images (TIFF, GIF, JPEG…) dans Acrobat via le menu Fichier > Créer un fichier PDF > A partir d’un Fichier…, ou plus simplement en glissant les images sur l’icône d’Acrobat.
Télécharger un exemple (900 Ko)
• ROC & OCR
ROC : Reconnaissance Optique de Caractères (OCR
en anglais).
Après avoir importé, et affiché le fichier image dans Acrobat il faut ouvrir « Dans ce fichier » dans le panneau d’outils Reconnaissance de texte.
A noter qu’il est possible d’effectuer les deux opérations en même temps : scan et OCR dans la foulée.

Chaque fichier image importé devient une nouvelle page dans Acrobat, s’il y en a plusieurs il faut indiquer celles qui doivent être traitées.
• Ensuite il faut « Modifier… » les options de Reconnaissance de texte

Langue : tenez compte de celle du document, pas de la vôtre 🙂
Style de sortie PDF :
• ClearScan (Acrobat version > 9) : synthétise une nouvelle police Type 3 qui simule approximativement l’originale et conserve l’arrière-plan des pages dans une copie basse résolution. Dans ce mode tout le texte est vectorisé, ce qui signifie que l’on peut zoomer sur la page en très gros sans avoir d’effet de pixelisation, l’option de sous-échantillonnage ne s’applique qu’aux images et n’a donc aucun effet sur le poids d’un fichier ne contenant que du texte. Une fois correctement optimisés, les PDF « ClearScan » sont pleinement utilisables avec les versions antérieures d’Adobe Reader (testé avec Reader 4). Il est à noter que cette nouvelle méthode produit des fichiers bien plus compacts, il suffit de comparer entre les deux exemples à télécharger ci-dessous.

Télécharger un exemple de PDF « ClearScan »
• Images indexable : rend le texte compatible avec la recherche et sélectionnable. Cette option conserve l’image d’origine, applique un redressement selon les besoins et insère un calque de texte invisible. L’option choisie pour le paramètre Sous-échantillonner les images dans cette même boîte de dialogue indique si l’image est ou non sous-échantillonnée et le niveau de sous-échantillonnage.
• Images indexable (exacte) : rend le texte compatible avec la recherche et sélectionnable. Cette option conserve l’image d’origine intacte et insère un calque de texte invisible (recommandée lorsque l’image doit être la plus fidèle possible à l’image d’origine).
Télécharger un exemple de PDF « Image indexable »
Contrairement aux apparences il n’y a que deux styles de sorties PDF puisque ‘Image indexable‘ donne le même résultat visuel dans les deux cas, il n’y a que la taille du fichier qui change, ainsi que le facteur de zoom utilisable (dépendant du sous-échantillonnage choisi). La version ‘compacte’ est en fait découpée en zones qui sont (fortement) compressées différement selon leurs caractéristiques, c’est le même principe que lorsqu’on découpe une image en ‘tranches’ pour l’exporter dans un tableau HTML.
Depuis la version 9 d’Acrobat les méthodes de compression ont été améliorées et donnent de meilleurs résultats (fichiers plus petits) que dans les versions antérieures, surtout en mode ClearScan.
Le choix dépend donc de la destination du document, dans le cadre de cet exercice il est préférable d’importer deux fois la même image et de traiter chacune différement, l’une après l’autre, c’est le meilleur moyen d’apprécier les différences.
La résolution finale dépend elle aussi de la destination du document, c’est un facteur important du poids du fichier PDF final.
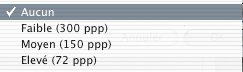

Sous-échantillonner les images réduit le nombre de pixels des images en couleurs, en niveaux de gris et monochromes suite à la reconnaissance optique de caractères.
Pour mémoire :
La résolution dépend de l’usage final du document, c’est un facteur important du poids du fichier PDF (voir cet article).
– 72 ppp conviennent à un affichage écran à 100 %. Mais il suffit de zoomer pour voir apparaître les pixels de l’image (effet Minitel). Et puis il faut bien un jour commencer à tenir du compte du fait que les (bons) écrans modernes affichent une résolution de 92 ppp minimum… Voir aussi : Le Web c’est pas en 72 dpi, coco !
– 150 ppp conviennent pour la restitution sur des imprimantes numériques (laser, jet d’encre…) et pour des documents écrans sur lesquels on souhaite pouvoir zoomer sans effet de pixellisation (jusqu’à 200%, donc).
– 300 ppp c’est la résolution utilisée par les presses offset des imprimeurs et par les presses numériques. Ca permet aussi de zoomer beaucoup plus sur les images à l’écran.
– 600 ppp c’est la résolution fréquemment utilisé pour les images monochromes, qui leur permet de conserver une meilleure finesse, sur papier comme à l’écran (option disponible dans Acrobat version ≥ 8).
Il n’y a plus qu’à valider les deux boîtes de dialogues et laisser le logiciel travailler.
• Correction
Le module d’OCR d’Acrobat a été complètement renouvelé dans la version 9 et encore optimisé dans la version XI (11), offrant à chaque fois des performances bien meilleures, surtout en ce qui concerne les caractères accentués.
Comme dans tous les logiciels d’OCR, la reconnaissance du texte n’est pas toujours parfaite et il est possible de corriger les mots mal interprétés ou sur lesquels il y a un doute, les ‘Suspects‘.
La ‘recherche des suspects’ est également réalisable dans un deuxième temps, après enregistrement du fichier. Il n’est pas impératif de le faire immédiatement.
Il est préférable de commencer par ‘Afficher les suspects trouvés‘, ce qui a pour effet de les encadrer de rouge, avant de demander à ‘Rechercher le premier suspect’.
L’image du premier mot sur lequel le logiciel bute s’affiche dans une fenêtre flottante pendant que la proposition correspondante est surlignée sur la page. Il n’y a qu’à taper le mot correct directement sur la page et/ou cliquer sur ‘Accepter et suivant’ si la proposition est bonne, ce qui est le plus souvent le cas. Il faut faire attention à cette étape car l’acceptation est irrévocable, il n’y pas d’annulation possible. En cas d’erreur il faudra revenir corriger le texte avec l’outil de retouche de texte.

• Rechercher les suspects
Suivant
permet de traiter le suspect ultérieurement, son image est conservée en attendant.
Une garde à vue illimitée, en quelque sorte…

• Enregistrement et utilisation
Le document papier d’origine est maintenant transformé en un document PDF (presque) comme un autre. La recherche est possible dans tout le texte du document (ne pas oublier d’utiliser l’Index incorporé disponible dans Acrobat 8 et versions ultérieures) et la recherche multi-document sera possible après indexation avec Acrobat Catalog, ou bien en utilisant l’Index incorporé dans un Porte-documents PDF (disponible depuis Acrobat 9).

